
性能考量#
目前,Flax nnx.jit 在纯 Python 中遍历对象图,这很慢并且会增加开销。为了解决这个问题,Flax 团队将开发一个名为 flaxlib 的 Rust 扩展,以加速 graph.py 中的一些遍历逻辑。这类似于 JAX 团队通过引入 jaxlib 来解决标准 JAX pytrees 的类似问题(请参考 Flax PR #4196 中的第一步)。
但是,有两点需要考虑:
开销仅与小型模型相关(请参考异步调度)。
您可以使用
jax.jit+flax.nnx.split/flax.nnx.merge来消除开销,以分阶段执行遍历逻辑(请参考降低 Python 开销)。
异步调度#
在 benchmarks/nnx_simple_training.py 中,我们正在增加层宽度(每层的特征数量)并测量使用 nnx.jit 和 jax.jit 训练的同一模型的总训练时间。
如下图所示,在达到某个模型大小之后,遍历所花费的时间会被异步调度完全吸收。当 Python 能够完成当前的 for 循环步骤,并到达下一个 train_step,而 JAX 尚未完成上一个 train_step 时,就会发生这种情况。
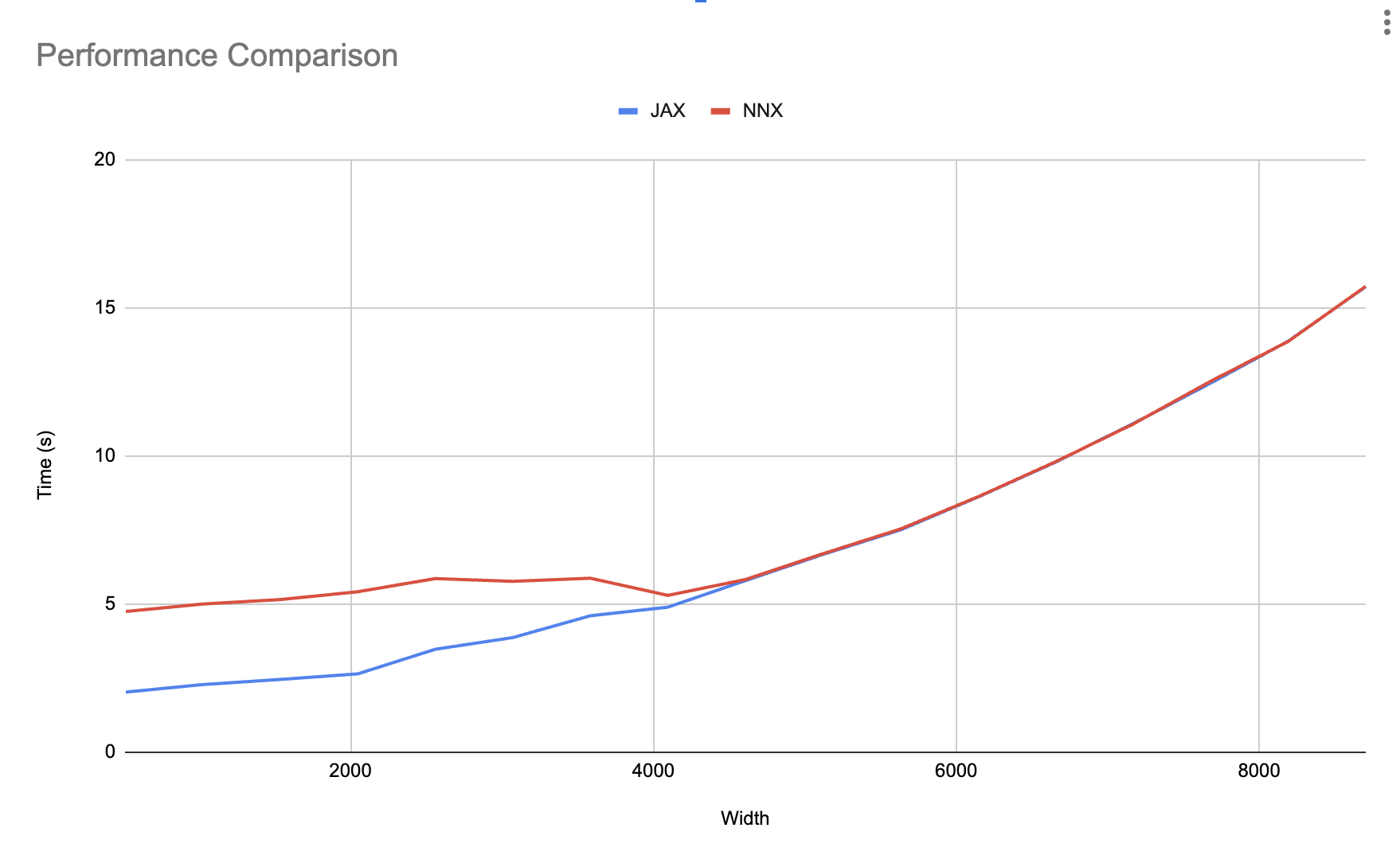
这意味着您只需担心小型模型的 nnx.jit 开销。如果您正在使用小型模型,请查看下一节,了解如何消除开销。
降低 Python 开销#
要消除 Python 开销,您可以将常规的 jax.jit 与 nnx.split 和 nnx.merge 结合使用,以分阶段执行遍历逻辑。
要学习如何执行此操作,我们首先创建以下简单的 Model
from flax import nnx
import jax
import jax.numpy as jnp
import optax
class Model(nnx.Module):
def __init__(self, din, dmid, dout, rngs: nnx.Rngs):
self.linear = nnx.Linear(din, dmid, rngs=rngs)
self.bn = nnx.BatchNorm(dmid, rngs=rngs)
self.dropout = nnx.Dropout(0.2, rngs=rngs)
self.linear_out = nnx.Linear(dmid, dout, rngs=rngs)
def __call__(self, x):
x = nnx.relu(self.dropout(self.bn(self.linear(x))))
return self.linear_out(x)
接下来,让我们创建一个使用 nnx.jit 的 train_step() 函数,该函数接收 model、optimizer 和 metrics,它们都是 Flax NNX 对象。
model = Model(2, 64, 3, rngs=nnx.Rngs(0)) # eager initialization
optimizer = nnx.Optimizer(model, optax.adam(1e-3)) # reference sharing
metrics = nnx.MultiMetric(
loss=nnx.metrics.Average('loss'),
)
@nnx.jit # <== currently slow
def train_step(model, optimizer, metrics, x, y):
def loss_fn(model):
y_pred = model(x) # call methods directly
return ((y_pred - y) ** 2).mean()
loss, grads = nnx.value_and_grad(loss_fn)(model)
optimizer.update(grads) # in-place updates
metrics.update(loss=loss)
return loss
for _ in range(10):
x, y = jnp.ones((32, 2)), jnp.zeros((32, 3))
loss = train_step(model, optimizer, metrics, x, y)
为了加速此过程,在开始训练循环之前,我们可以对 train_step() 的所有 Flax NNX 对象输入使用 nnx.split,以创建遍历速度更快的 graphdef 和 state pytree。
接下来,我们更改 train_step() 以接受 graphdef 和 state,并在 train_step() 的开头和结尾使用 nnx.merge 和 nnx.split,以便在对象及其 pytree 表示之间来回切换。即使 nnx.split 和 nnx.merge 很慢,也无关紧要,因为它们只会在跟踪期间运行一次。
完成此操作后,我们可以更改 train_step() 函数以使用 jax.jit 而不是 nnx.jit
model = Model(2, 64, 3, rngs=nnx.Rngs(0)) # eager initialization
optimizer = nnx.Optimizer(model, optax.adamw(1e-3)) # reference sharing
metrics = nnx.MultiMetric(
loss=nnx.metrics.Average('loss'),
)
# split before training loop
graphdef, state = nnx.split((model, optimizer, metrics))
@jax.jit # regular JAX
def train_step(graphdef, state, x, y):
# merge at the beginning of the function
model, optimizer, metrics = nnx.merge(graphdef, state)
def loss_fn(model):
y_pred = model(x) # call methods directly
return ((y_pred - y) ** 2).mean()
loss, grads = nnx.value_and_grad(loss_fn)(model)
optimizer.update(grads)
metrics.update(loss=loss)
# split at the end of the function
_, state = nnx.split((model, optimizer, metrics))
# return new state
return state, loss
for _ in range(10):
x, y = jnp.ones((32, 2)), jnp.zeros((32, 3))
state, loss = train_step(graphdef, state, x, y)
# update objects after training
nnx.update((model, optimizer, metrics), state)
请注意,我们仅对 jit 执行此操作。您仍然可以使用其他 Flax 转换,例如上面示例中显示的 nnx.value_and_grad,因为它们的开销已经被外部的 jit 吸收。
并且在训练循环完成后(或在需要时),我们可以使用 Flax nnx.update 将 Flax NNX 对象(如 model、optimizer 和 metrics)更新为新的 state。